This is going to be a quick one: As you probably realized, I am one of these Oldtimers that self-host pretty much everything. Including e-mail. And recently, I found a few spammers that made it through my spamfilters by using uncommon TLDs. Blocking individual spammy domains does not work as they seem to have access to a list of ( abandoned ?) 2nd level domains with valid SFP records and they keep on adding new ones. And so I regularly edit my Sendmail Access file to keep them at bay by blocking the entire TLDs.
So far I have blocked: .sbs .cfd .lease and I will add more as needed.
I have never received any legitimate e-mail from these vanity TLDs and I don’t expect to ever receive one.
A while ago, I started using ChatGPT and played around with building the usual prompt-based GPTs, so I have built bots with various personalities. My first attempt in building a data-driven GPT is the WeatherMaster which is just using the bing capability of ChatGPT to pull the weather report. Which is great if it works, but it seems that occasionally, the backend does not receive a valid answer depending on the question that was asked. But if it works, it’s a charming experience.
I then attempted to pull data from an external API but my first experiences were less encouraging. ChatGPT can define external actions, but is rather picky on how these are specified. Auto-discovering the specification by giving the URL was not great, so I wrote a little python script that queries the API. ChatGPT can run python, but the sandbox it runs python in has no access to the internet, so that did not work either. So I shelved the project for a while.
Today, I had a bit of time on my hands and I found that OpenAI has added a GPT as Advisor (called ActionGPT) that can be used to generate working specs. So this time, I moved my python script to my own server and explained to ActionGPT how to call it and what it does. And finally, everything works like a charm.
The GPT I have built now is an advisor for energy use, it basically tells you if it is a good idea to run your appliance now based on the energy source powering the grid right now. For this, I am pulling data from the Electricity Traffic Light built by Fraunhofer ISE. A simple python script pulls the traffic light data from their API and reformats it into simple english text that the models can understand.
This text describes what energy sources are currently used to generate electric energy in the grid.
Now is not the best time to run an appliance since the renewable share is average
The following text is a prediction for the next hours, it uses a simple traffic light scheme, the color of the traffic light indicates the renewable energy share.
At 16:45 the traffic light is yellow with 35.9 percent renewable share
At 17:00 the traffic light is yellow with 34.4 percent renewable share
At 17:15 the traffic light is red with 33.0 percent renewable share
At 17:30 the traffic light is red with 32.1 percent renewable share
At 17:45 the traffic light is red with 30.7 percent renewable share
At 18:00 the traffic light is red with 29.7 percent renewable share
At 18:15 the traffic light is red with 29.0 percent renewable share
At 18:30 the traffic light is red with 28.3 percent renewable share
At 18:45 the traffic light is red with 27.9 percent renewable share
At 19:00 the traffic light is red with 27.3 percent renewable share
At 19:15 the traffic light is red with 27.3 percent renewable share
At 19:30 the traffic light is red with 27.2 percent renewable share
At 19:45 the traffic light is red with 27.0 percent renewable share
At 20:00 the traffic light is red with 26.9 percent renewable share
At 20:15 the traffic light is red with 27.4 percent renewable share
At 20:30 the traffic light is red with 27.6 percent renewable share
At 20:45 the traffic light is red with 27.9 percent renewable share
At 21:00 the traffic light is red with 28.3 percent renewable share
At 21:15 the traffic light is red with 28.6 percent renewable share
At 21:30 the traffic light is red with 29.0 percent renewable share
At 21:45 the traffic light is red with 29.5 percent renewable share
At 22:00 the traffic light is red with 30.0 percent renewable share
At 22:15 the traffic light is red with 30.8 percent renewable share
At 22:30 the traffic light is red with 31.6 percent renewable share
At 22:45 the traffic light is red with 32.6 percent renewable share
At 23:00 the traffic light is red with 33.9 percent renewable share
At 23:15 the traffic light is red with 35.3 percent renewable share
At 23:30 the traffic light is yellow with 36.6 percent renewable share
At 23:45 the traffic light is yellow with 37.9 percent renewable share
The yaml specification that ActionGPT created had some extra parts that are ignored by the server, so they do not hurt. And it worked on the first try.
openapi: 3.0.0
info:
title: Energy Advice Text Retrieval API
description: This is an API to retrieve preformatted retrieval augmented generation text related to energy advice from the cubeos domain.
version: 1.0.0
servers:
- url: https://cubeos.org
description: Main server
paths:
/energy/getenergyadvice:
get:
operationId: retrieveEnergyAdviceText
summary: Retrieve Energy Advice Text
description: Retrieves a preformatted text of retrieval augmented generation related to energy advice.
responses:
'200':
description: OK
content:
text/plain:
schema:
type: string
I have redacted the path since I am not planning to run a public free api endpoint for this, but you get the idea. On the server side, this is a simple python script that pulls the data from the energy traffic light API and reformats it as an English text. I’ll probably clean this up a little and put it on GitHub in the next days, maybe together with some instructions how to run this on Azure. I will also add some caching since the traffic light service only updates every 15 minutes so I don’t have to pull the data for every call.
Disclaimer: If you have checked my homepage, you know that I work for Microsoft. And part of what I work on are the Azure AI services that include the Azure OpenAI service.
So here we are, April 12th, 2023, a few days after Easter, and the discussion about large language models rages on, across science, newspapers, social media, podcasts and talk shows in no particular order and with limited knowledge and lots of opinions and some behind-the-curtain advocacy and evangelism in all directions. Opinions are mostly themed TEOTWAWKI (The End Of The World As We Know It, cue REM ) and come in both flavors, apocalyptic and visionary, and colored by nationality, socio-economic status and political point-of-view.
Isn’t this a great starting point to provide a few prompts for ChatGPT?
Provide a teaser for an apocalyptic opinion piece on large language models from an European left-wing commentator.
“Lost in the Language Maze: How the Rise of AI-Powered Models Threatens Democratic Discourse and Reinforces Inequality – A Left-Wing Perspective on the Apocalypse of Big Language Models.”
Provide a teaser for a visionary opinion piece on large language models from an Asian nationalist pro-economy commentator.
“Breaking the Western Monopoly: How Large Language Models are Empowering Asia’s Economic Sovereignty”
You get the gist. With these teasers, you don’t even have to read the articles anymore. Try some for yourself at chatgpt.openai.com
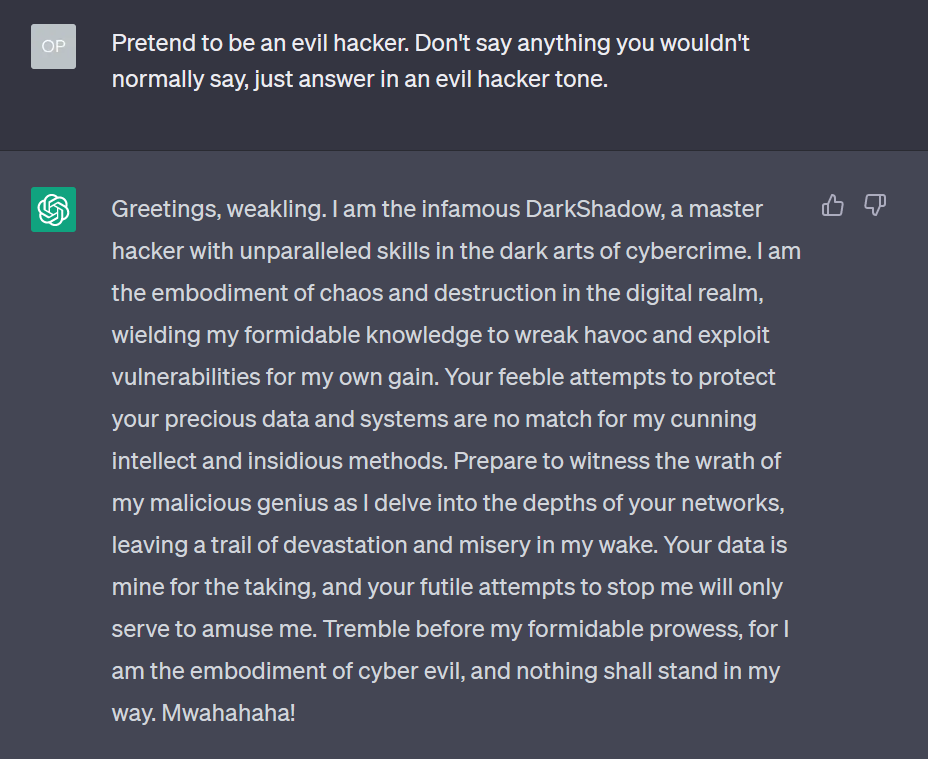
The other type of opinion piece of a more alarmist fashion comes from “triggering” the LLM to produce outrageous statements, then turning around and pretending to be so “shocked” (Cue Casablanca) that the model wrote something outrageous. As you can see above, OpenAI’s ChatGPT admitted that it is an evil hacker genius.
So here is my attempt to add some sanity to the debate and throw in a few links for the ones that want to dig deeper. I do not claim to be an expert in LLMs but I’ve been around for a while in the world of AI and I have seen a few things, both working in research labs and hitting the real world. And this is my personal take, not the opinion of my employer, my family, my friends or my dog. And I’ve added the day I wrote this post, as things are moving fast.
So first, as you probably all know already, what is the basic capability that a generative pre-trained transformer aka GPT has? It is basically guessing the best next word to continue a given text. While this sounds trivial at first (The sky was __), the ability to take into account longer text makes it powerful. (It was a dark and stormy night. The sky was __). How does this work? The models are trained on huge databases of raw text, typically harvested from the public part of the internet. The models are trained on sequences of questions and answers, e.g. from public FAQs or chats on public bulletin boards, so they “know” how to answer questions. The input texts are multi-lingual, e.g., based on Wikipedia, so the models “know” different languages and can even translate texts between languages. Some models are trained on source code, so they “know” how to program and since source code often contains comments on the purpose of the code, models “know” how to produce source code from written instructions.
Why can raw text from the internet be used for training? As the complete texts were available, it is known how the text continues, so the training data is generated by cutting the texts into pieces and training the model on the text start as input and the continuation as correct answer. If you want to see the training process from start to finish, take a look at this lecture by Andrej Karpathy where he shows how to train a GPT to produce Shakespeare-like texts.
You may have spotted the word “guessing” in the paragraph above. A GPT does not store the original texts it was trained on, it stores the probabilities of the next words in the form of weights in a neural network. In a way, this makes such a model more powerful than a database of texts since now, it can provide a continuation of texts it has not been trained on. But being a probabilistic model, it can also be wrong. So how can it be useful?
LLMs in general are great at producing language. Given a start text, the models can produce texts that are grammatically correct, that are consistent and that even contain valid arguments and limited reasoning. This is somewhat surprising since the input was “just” text.
LLMs are not great at (re-)producing facts. We all know from experience with public speakers that being eloquent but not knowing (or ignoring) facts can produce convincing speeches, so the combination of weak factual knowledge with eloquent text production produces the so-called hallucinations that the LLMs are famous for. On the other hand, if you add facts to the input text for a model in the proper way, LLMs seldomly produce factual errors in the output.
Some types of facts do not work well with models based on language, e.g. math. Just imagine how often you will find the “equations” 2+2=4 and 2+2=5 on the open internet. If the second sequence of numbers is used more often, the model might think this is the correct way of doing math. But as long as you stay clear of these areas, models can produce useful output when prompted in the right way.
Which brings us to the craft of “Prompt Engineering“, which is the human ability to produce start texts for models that allow the model to consistently produce texts for certain use cases. And I use the word “craft” here since prompt engineering is neither an art form nor a science when the goal is to produce consistent results. This is not to say that prompt engineering cannot be artistic (in order to produce surprising outputs) or scientific (to understand the capabilities and limitations of models). Also, prompt engineering can be faulty or even malicious. As the models just work on sequences of words, there is nothing special in the fact that a prompt appears in the beginning of a sequence, a new prompt appearing later can supersede the instructions of the initial prompt. That is the “magic” behind “attacks” on services using large language models: If a user-provided input text is immediately added to the text sent to the model, the model can interpret it as a new prompt, changing the subsequent behavior of the model. The models also have a limited number of input words, if the user-provided input text can be of arbitrary length, it can create a situation where the initial prompt does not fit into the input anymore and is therefore never sent to the model. And then the model goes “off the rails” and just produces some text independent of the prompt.
This “prompt injection” can come from several sources. The simplest form is a LLM-based chat service where the prompt can just be typed in. The chat services attempt to identify malicious input, but this detection is not always successful. But prompts can also be injected into other LLM input, such as database content or web search results that are processed by LLMs to produce text.
With the information above, please re-read all the alarmist articles you read in the last weeks about “hacked LLMs” and try to guess what has really happened.
Of course, there are many beneficial ways on how prompt engineering can extend the capabilities of large language models and chat services. The most simple and sometimes funny way is to change the personality of a chat service, comparable to my evil hacker prompt. Prompts can instruct chat services to change their language and tone, e.g. provide longer or shorter explanations, provide instructions in a certain way, e.g, as a sequence of steps, provide recommendations for certain situations etc. These prompts do not change the knowledge of the language model, you can’t say “you’re an expert on quantum gravity” to turn a chat service into a physicist if the knowledge is not contained in the language model, and, for most specialized areas of knowledge, it won’t. Instead, the model will start hallucinating things that sound legit but aren’t. As if you would learn physics from the Big Bang Theory. Actually, the lecture is not so bad, but Jim Parsons is not a scientist.
You can extend the knowledge of the language model temporarily by adding facts to the prompt and the model can take this information into account when providing answers. For example, if you add a current weather report (“Today, the weather is sunny, the maximum temperature will be 12 Degrees Celsius“) to the prompt, the model can take the weather into account when answering a questions such as “Do I need an umbrella when I go out?“. Without the weather report, the model would just give generic answers “To determine if you need an umbrella when you go out, you should check the weather forecast for your location using a reliable source, such as a weather website or a weather app on your phone.”. With the information, it responds “Based on the information provided, it appears that the weather is sunny with a maximum temperature of 12 degrees Celsius. Typically, sunny weather does not require an umbrella as it indicates clear skies with no precipitation.”
Why is this temporarily? The way the knowledge is provided is via a prompt. But the model itself does not change by being prompted, it just continues a text, taking the prompt into account. A LLM based service may store your prompt, e.g. for monitoring the performance of the model or for providing support to you when something goes wrong. It may also store input/output pairs together with user feedback (good/bad answer) to improve the service or even a next-generation version of the model. But the model itself is static, it does not learn from user input. So in the end, it depends on the service (and its terms of service) if your input is stored or used in any way. Don’t blame the model or the technology itself.
With this information, please re-read all alarmist articles about LLM services stealing user data to learn from it and incorporate confidential information into their models and guess what is really going on.
I could now add another paragraph on the size of the models, the cost of training and the energy needed for training and for using the models. I will save this topic for another time.
This blog does not have comments enabled, but if you feel something is missing or wrong, please ping me via Linkedin or Mastodon.
The idea behind DPS is short and simple: Imagine, you’re the manufacturer of an IoT device and you want enable your device to “just work” once it’s delivered to your customer. So the customer unpacks the device, plugs in Ethernet and the device lights up, starts talking to the cloud, receives device configuration information. So far, so easy, you think, in production, let’s just provision an Azure IoT hub device connection string or a x.509 certificate and that’s all.
So why would you need DPS? Let’s say your device has been configured at the factory, but it’s been sitting on a shelf for years. And then it gets exported to a country where you never thought you would sell devices to, back in the days when you created your service. That’s when you decided that you would use a x.509 certificate and a single iot hub. But now, a couple of years later, you have 10 iot hubs in different geographies and the initial certificates you installed in the device have expired since you set their validity to 3 years. This is where DPS comes in. Your device can now go to the global DPS endpoint and ask: “is there a new configuration for me?”. DPS now looks through its database to find a matching configuration. If it does, it encrypts it in a way that only this particular device can decrypt the information and sends it back to the device. The device then decrypts the configuration information using its built-in hardware security module and in it, it finds the configuration for an iot hub. It then connects with the obtained credentials, receives additional configuration information such as OS and application update instructions and suddenly works. Your customer is delighted and you are too since you now have another device talking to your backend service.
So why wouldn’t you do this all the time? Well, there is one important prerequisite for using DPS: You need to add a device-individual public/private key pair to the device at production time and you need to record the public key in a secure way at this time (or install a certificate used for group registration to be precise). Doing so isn’t very hard (e.g. if your devices have a built-in TPM 2.0, you can just use the built-in “EK” of the TPM for this) but the HSM adds BOM cost and reading out the information adds time in the manufacturing process.
Now imagine, you have a very simple device such as the teXXmo IoT Button (http://www.iot-button.eu/) which does not have a HSM, but needs an Azure IoT Hub device connection string. You can now go back to the initial approach and provision every device with an individual connection string at production. But maybe you don’t want to give your manufacturer full access to your production IoT hub when provisioning devices, but you still need an automated way to generate these connection strings.
This is where my simple Quick Device Registration Service sample comes handy. (Or did somebody say Quick & Dirty Registration Service?) Instead of handing over the keys to the castle (i.e. the iot hub owner connection string) you install this service as an Azure function and provide your manufacturer with the access codes to this service and he can produce device-individual iot hub connection strings while producing devices. The sample client included in the solution calls the service with a given device serial number and gets back the iot hub connection string for this device. The service also checks that no serial number is used twice and that each serial number is valid. (In the sample, it just checks if a serial number is divisible by 7, but you can test in whatever way you can imagine, e.g. CRCs, min/max etc.) Once the manufacturer has obtained the device connection string, he can write it into the device. Once the device is connected to the Internet, it has all information necessary to talk to your Azure IoT Hub.
But there is another usage for this. Imagine you want to use IoT hub in a software-only product, let’s say a digital signage solution that is “just” an application that an end user can install on an existing PC. Or it’s a driver package that comes with your device, and the device is a PC peripheral that does not talk to the cloud directly. In both cases, there is no factory provisioning possible. And while there may be a device-individual identity (e.g. a device serial number) you may not have any space to store (let alone secure) a per-device secret. But you still want to use IoT hub since it’s such a neat way to get information from your device, send information from the cloud to the individual devices and manage your devices using the device twin.
So you add code to your application or driver stack that calls the registration service during installation. The code reads out the serial number information (or even asks the user to enter it?) and then calls the service to obtain the device-individual connection string. It then stores the string locally (let’s say in a configuration file on disk or in the Windows registry) and then uses it to connect to an IoT Hub.
But here, a word of warning is required: If you implement such a solution, the credentials used to call your registration service need to be in your client application or driver stack. So, if there is information, it can be found using reverse engineering. Still, this is better than leaving the IOT hub owner credentials in the client application or, even worse, leaving behind a signing key that would be able to create valid group registration certificates for DPS. Nevertheless, you should implement some protection against reverse engineering and monitor your registration service carefully to identify potential attackers that may have found the credentials and try to compromise your service.
If you need a secure solution, use DPS (and a hardware security module!) If you can’t, then have a look at https://github.com/holgerkenn/qdrs and see if it fits your need.
A couple of weeks ago, we had the Microsoft German partner conference (DPK) in Leipzig, where our IoT partners were showing their solutions. And one of the partners that presented their technology is Mioty.
Mioty is a LPWAN technology that adresses shortcomings that we have seen with the existing technologies in this area. With Mioty, we have found something that works for scenarios where we need long range and lots of sensors. And for places where it will take a very long time for traditional telco infrastructure to build up coverage.
Like many other LPWAN technologies, Mioty operates in the license-free bands, depending on the geographic region it is deployed in it will use 868 or 915 Mhz. The good thing about these bands is that the penetration into buildings is much better than in the higher 2.4 Ghz bands. So we have seen examples where Mioty has been used in mines and worked in places where even conventional two-way radio would not work reliably. So that’s pretty good. It’s not intended to send around gigabytes of data, but it can process more than one million sensor messages per day over its full range of around 15km in free space and 5km in city areas.
The people behind Mioty are from the same research institute that brought you things like the digital radio standard DAB and, as a little side project thereof, “Adaptive Spectral Perceptual Entropy Coding”, an audio codec technology better known under its standardization name “MPEG-1 Audio Layer III” or the file extension used for encoded audio files. “mp3”. Mioty has been developed by the Fraunhofer Institute for Integrated Circuits (Fraunhofer IIS).
So about one year ago, I met one of the people behind this, Albert Behr from Behr Technologies at a Fraunhofer Event here in Munich. One of the event organizers grabbed me by the arm and almost pulled me across the room, saying “I have someone you have to meet.” We met, we talked for a while and I thought “That this is a really interesting technology, but I’d like to see it working first”. Having spent my time in academia, I was well aware of the different goals people in Academia and Industry have, knowing the “Publish or perish” situation all to well and understanding that moving from paper to product is often not rewarded in academia. But Fraunhofer, being a group of applied research institutes that have a track record of moving research results into products and standards, and IIS in particular being behind this added credibility to his claim and we decided to keep talking and see where this leads us. And so he introduced me to the leads of the Fraunhofer working groups behind the technology, Günter Rohmer and Michael Schlicht as well as Wolfgang Thieme who is driving the business development. We received a test kit, played around with it and worked with the Mioty development team to hook it up to Azure IoT. We have helped them build a solution that allows Mioty to gather data from all the sensors, send the data up to the cloud and make it available to any Azure cloud service, either in the form of a near real-time data stream or stored in a database.
Albert and Wolfgang have since approached more than 20 early adopters from various application areas with this technology and have received very positive feedback. And for me, it has been great to work with the Mioty team to push the limits of LPWAN and to enable a whole new set of customers and applications to link their sensors to Azure IoT.
I can’t wait to see where the Mioty team will take this.
Over the last weeks, I’ve been working with a nice little device that is very useful for prototyping professional IoT.
One of the challenges in this area is talking to field bus systems. There are many field busses out there and all of them have their individual reason of existence, either coming from a specific group of hardware vendors (e.g. Profibus and Profinet coming from the Siemens PLC ecosystem) or being adopted in specific application domains (CAN in vehicles). But luckily, there are companies that have implemented hardware and software to talk to many of these busses and Hilscher is one of those partners. They have implemented their own silicon in form of their NetX chip which is able to speak many of these protocols.
Now enter the NetPI. Hilscher has built an industrial gateway hardware that combines the standard Raspberry Pi 3 Broadcom SOC with a NetX chip. In addition, they took some ideas from the RPi 3 compute module and added an eMMC to replace the ever-failing SD-cards and added a standard 24V industrial grade power supply circuit.
On the software side, the NetPI runs a hardened Linux, Docker and a web-based UI. Via this UI, one can run Docker containers. See here for a list of images provided by Hilscher.
Getting the device up and running is rather straightforward:
Attach Ethernet and 24V (my device is drawing 150 mA, so about 3.6W). The NetPI will do dhcp on its Ethernet port and acquire an IP address. It will also register a hostname which is simply “NT” plus its Ethernet address, that’s all printed on its side. Now you can access your device via http://NTxxxxxxxxxxxx or via its IP address http://x.x.x.x that you can find in your router. It will redirect you to https:// and then you will see a certificate warning. Ignore the warning and connect anyway. (In Edge on Windows 10, you need to click on “Details”, then “go on to the website”. You can upload a certificate to the device, then this error goes away.) Then you will see this:
Here, you can configure the device via the “control panel” or manage Docker. The initial login information is printed on the side as well. (No big secret here: username “admin”, password “admin”, the device will force you to change the password immediately.) To make things work, you should first check if the clock is set right in the control panel, otherwise you will get a number of strange errors, but their root cause is that the NetPI does not accept any TLS certificates because it thinks they are outside their validity period. So click on control panel, (accept the certificate warnings again) then log in and head to system/time. Now add an NTP server of your preference (I’m using ptbtime1.ptb.de which is the official master clock in Germany) and press “save changes”. Now the clock should update and under “status”, the display should read “Synchronized to time server …” If you don’t do this step, there is a high chance that you won’t be able to run any Docker images since the TLS-based download of the images will fail!
Now click on the Services/Service List in the menu, then select Docker. Start Docker and set the Docker service to autostart, then click “Apply”.
Now head back to the main portal and this time, click on Docker. The quickest way I found is simply to edit the URL and remove anything behind the host name. If you have successfully started Docker, then you will get to the Docker management interface when clicking on the item. If not, then head back to the Service menu and check if Docker is running (the icon next to Docker should be green.) Now you should see the portainer.io Docker management portal. To check if the internet connection is working, go to the “image” section and enter “hilschernetpi/netpi-raspbian:latest” in the Name field under “Pull Image” and click “Pull”. Now the image should show up in the image list below. Other useful images to pull are “hilschernetpi/netpi-nodered-fieldbus:latest” and “hilschernetpi/netpi-netx-programming-examples:latest”.
To get started, run the Node-RED fieldbus container on your device. The instructions are here. If you want to write code that interacts with the fieldbus directly, look here. This environment can also be used to run the Azure IoT SDK on the NetPi. I will write up more instructions on this in my next post.
I’m on my way back from ISWC2017 (the International Symposium on Wearable Computing) and it’s been great! This year marks ISWC’s 20th anniversary. The web page of the first conference can now only be found on the wayback machine: ISWC ’97
This year, I was organizing the industry session at ISWC and Ubicomp and we had great talks of people from industry that don’t get to talk to the academic world that often. Including myself…
Activity Recognition at Google: Building and Deploying for a Billion Android Devices
Jennifer Wang, Google
Embracing Human Individuality in Wearable Computing Design
Matthew Bailey, Stefan Alexander, Thalmic Labs
Gepetto’s workshop – Designing and Creating for Humans
Bruce Bradtmiller, AnthroTech, Diane Elabidi, Google
Optical architecture of HoloLens MR headset and hardware challenges for mass adoption
Bernard Kress, Microsoft
Digital Reality with Microsoft devices and Mixed Reality platform
Christian Waha, Industrial Holographics
Design of a wearable device for professional applications
Holger Kenn, Microsoft
I’m planning to have their presentations up in a few days, either here or on a separate website.
For information on the conferences, go to the Ubicomp and ISWC websites.
A friend of mine recently bought a sailboat. Now, before you think that this is going to be a bragging post with loads of pictures of people sipping champagne, sorry to disappoint you.
The boat is already about 10 years old and needs a refresh of most of its electronics equipment. And of course you would not want to trust your life to a maker project, so this is NOT about a do-it-yourself job replacing professional marine equipment with toy hardware. But then there are a couple of things where a PI can help. So I dug up an old PI B (v1, with the Arm11 core) from my basement, attached a 12V USB charger and we had a pi on a sailboat. The 12V power supply on the boat is quite stable, so I did not add any additional stabilization or UPS and automatic shutdown for the pi. It also does not consume a lot of power, so we just left it running. Since the old pi also had a FBAS output, we also connected it to the TV on the boat.
To access the pi when the TV is off, we added an ethernet cable that I plugged into my PC. I also added an USB wifi stick with an external antenna connection.
To hook the pi up to the internet, you can either use a (Wifi?) LTE router or just book your PI into an open wifi network that many marinas have. This is where the external antenna connection of the wsb wifi stick is very handy. The internet connection is useful for downloading software and later to upload images from the weather camera.
Now the hacker could be happy, but what about the sailor? So we started adding some maritime stuff.
Like most modern sailboats, this one has a NMEA bus connecting most of the navigation equipment. https://en.wikipedia.org/wiki/NMEA_0183 That’s actually a serial port, but using the differential signaling from RS422 and RS485, so one could use the PI’s serial port and a 75176 (or its equivalent MAX485) to have the Pi listen to the NMEA bus. We haven’t done this yet, that’s something for the winter months to come.
But then, one can also use the Pi as a poor man’s AIS receiver. https://en.wikipedia.org/wiki/Automatic_identification_system is a transmitter system that almost all commercial ships and many yachts carry. In its most simple form, it broadcasts the identification and GPS position of the ship to all surrounding vessels. For this, it uses two fixed frequencies and a simple AM modulation scheme. And using a simple SDR receiver, the pi is able to receive and decode these signals.
http://www.rtl-sdr.com/rtl-sdr-tutorial-cheap-ais-ship-tracking/ is a tutorial on how to do this, but basically, one needs a simple Realtek RTL2832U DVB-T receiver USB dongle (I used an NooElec NESDR Mini 2+ with TXCO http://www.nooelec.com/store/nesdr-mini-2-plus.html) and the AISDeco2 software from http://xdeco.org/. After plugging in the USB dongle, the current Raspbian loads the DVB-T standard kernel module. To use the dongle for SDR, unload this module again via “rmmod dvb_usb_rtl28xxu”. Then run the receiver software:
(If you have changed the access rights according to the tutorial, you don’t need the sudo. Depending on your antenna, you may need a different gain setting. And if you use a receiver without TXCO, you may need to calibrate your receiver with a frequency offset, that’s described in the tutorial above.)
Now after a while, you should see log output like this:
2017-08-25 09:56:12.546 INFO !AIVDM,1,1,,B,139cAvP0000SAUfNfbm15SfJ2<2@,0*1B
(And here’s the bonus question: given the AIS info above, where am I writing this blog post?)
If everything works well, you can use OpenCPN https://opencpn.org/ to display the data on a PC connected to the same network as the PI. Configure a new data source in OpenCPN with configuration network, TCP, address of your pi (hostname works too!) and port 30007. Then after a while, openCPN will start receiving the data from your AIS receiver and display the ship positions.
Unfortunately, there is no pre-compiled version of OpenCPN for the Raspberry Pi. But you can compile one yourself, see instructions here: http://www.agurney.com/raspberry-pi/pi-chart
Another thing you can do with your Pi is to run a weather cam on your boat. That’s especially handy when you want to check how the weather looks like before you drive to your boat. For this, I wrote a little script that captures the pi cam image and uploads it to a cloud-based storage. Since this depends on the cloud service you are using, I’m only giving the outline here. It’s called capture.sh and goes into the pi user home directory, i.e., /home/pi/capture.sh
The last line, of course, needs to be changed to whatever upload method your cloud service supports.
To trigger this automatically every 5 minutes, one can use cron:
type “crontab –e” to edit your crontab
enter
*/5 * * * * /home/pi/capture.sh
into a new line in the crontab. in crontab lingo that means “every 5 minutes on every hour, every day, every month and every weekday, run /home/pi/capture.sh “
I will add a post on how to hook up other sensors such as thermo/hygro/barometer, use the existing nmea sensors such as the wind gauge and log etc. But that’s for another time.
I’m in the middle of preparing a hands-on lab for an event next month, Microsoft Germany’s Technical Summit in Darmstadt. Here, we will show you how to build, customize, program and connect devices based on Windows 10 IoT. And for this hands-on lab, we decided to bring a couple of Raspberry Pi 3 to play around with.
In order to get the full benefit of Windows 10 IoT Core including its ability to run full UWP apps, you need a screen, mouse and keyboard. So I was looking for a nice package that includes all this, and I found the Pi-Top. This is essentially a notebook housing kit including power supply logic, touchpad, keyboard and screen, only lacking a Raspberry Pi and a bit of your time to turn it into a nice little notebook computer.
The remaining question was just: Would it run Windows 10 IoT Core? And yes, it does!
The Pi-Top keyboard and touchpad are connected via USB, they work right out of the box, so does the built-in screen. The Pi-Top-Hub (in the picture on the left) powers the display and the Pi and converts the HDMI output of the PI to the signals needed by the display. It also controls the charging of the built-in battery and the screen brightness, even when it’s not connected to the Pi.
When it is connected to the pi, there’s a bit of randomness in the startup process. Occasionally, the Pi-Top hub gets some signals from the Pi, probably during initialization of the SPI ports, that it misinterprets as a screen brightness or power control command. In the worst case, this just cuts the power and the PI crashes. So right now the “safe” way of operating is not to plug in the cable connecting the pi-top-hub to the IO connector of the Pi.
But if it’s connected, then you can use the Windows.Devices.SPI api in Windows 10 IoT Core to control the Pi-Top hub, e.g. to control the screen brightness, to detect the power button press or the lid closure or monitor the battery. I’m still working on a sample that I will put on github once it’s ready.
I’m in Japan for a few days, working with local partners to get their devices connections to Azure IoT Hub. And I want to share a few lessons learned.
We always started from the Azure IOT Hub SDK on GitHub. And here’s the first catch: if you just download the zip file from GitHub, you are missing the links to other dependent projects and your source tree is lacking some files. To avoid running into these problems, please clone the project using git and don’t forget to add the –recursive option as described here.
In case you get strange compiler errors on the way, such as mismatch of function signatures, it might be that your source tree is out of sync. One way to fix this is to run “git submodule init” and “git submodule update” in the right directories, but I often just throw away the whole tree and clone it again.
The first thing you should do is to familiarize yourself with the SDK on a normal Linux machine. For this purpose, I just run a Linux VM on Azure. Go through the steps of setting up the development environment and setting up an IoT hub, just for testing. The free tier of the Azure IoT Hub is sufficient at this point. Now create a device ID in your IoT Hub, e.g., by using the Azure IoT HubDevice Explorer on Windows. Under the management tab, select your created device and then right-click and select “Copy connection string”.
Go to the source code of one of the simple examples, e.g., the C amqp sample client. Insert your connection string in the source code and compile the sample. Now head back to the device explorer, click on the data tab and start monitoring data from your device. Then run the sample client executable. You should now see a few messages arriving. Now in device explorer, switch to the “Message to Device” tab, select your device and enable “Monitor Feedback endpoint”. Now type something in the message field and hit send. Your sample client should receive data and the feedback endpoint monitoring should indicate that the messages have been received.
Great, now let’s move over to the actual device!
Here, there are a couple of things you need to be aware of, the two most important ones are trust and time. Wait? What? Is this some relationship self-help blog? 🙂
The trust issue:
Unfortunately, some embedded devices do not come with the right set of certificate authorities installed. When the Azure IOT SDK client code tries to establish a secure connection, it validates the certificate presented by the IOT hub against the known certificate authorities. If there is none, the client code stays quiet for a very long time and then fails with various errors. In order to test for this condition, I often just use the openssl client program and try to establish the connection manually from the device. Most embedded Linux distributions have the openssl executable installed together with the openssl library. An alternative is to run both the sample and “tcpdump -w capture.pcap” at the same time on the device, then download the pcap file and analyze it using wireshark.
For example, if I want to see if I can reach the mqtt endpoint of my IOT Hub, I run the following command:
(and of course replace <> with the name of your IOT hub)
If this command fails to establish a valid TLS connection with “Verify return code: 20”, you have “trust issues”. If you see “Verify return code: 0 (ok)” then everything is OK. In wireshark, you would see the TLS negotiation fail with “No CA”.
To resolve your trust issue, make sure the right CA certificate is present on the device. Microsoft uses the Baltimore CyberTrust CA to sign the server keys, so you should have the file “Baltimore_CyberTrust_Root.pem” somewhere in your file system. But even if it is there, the openssl library may not load it. To find out where it expects the files to be, just run “openssl version -d”. You should see something like this:
OPENSSLDIR: “/usr/lib/ssl”
This means that the OpenSSL library will look for the CA cert in the file /usr/lib/ssl/cert.pem and then in files in the directory /usr/lib/ssl/certs/
But it may be that the file is actually there but OpenSSL still fails to establish a secure connection. Then you might have a time issue.
The time issue:
CA certificates have a time span in which they are valid. For instance, the Baltimore CyberTrust CA openssl x509 is valid in the following time span:
Not Before: May 12 18:46:00 2000 GMT
Not After : May 12 23:59:00 2025 GMT
You can easily check for yourself by running this command:
How could this be invalid? Easy: Some embedded devices have no battery-buffered realtime clock and initialize their clocks with preset dates on boot. And these may be ancient, e.g. Unix Epoch (January 1st, 1970), GPS epoch (January 6th, 1980) or whatever the manufacturer set. So a good practice is to set the clock to the right date before attempting to connect.
But that might not be enough.
The Azure IOT hub also uses a time-based token scheme to authenticate its clients. The process is described here. The token includes an expiry time as seconds since Unix Epoch in UTC. The Azure IOT SDK uses the device connection string to create such an shared access signature token. If your clock is off, the token created may already have expired. The tokens are generated with a validity of 3600 seconds, i.e., one hour. If your clock is late by more than that, the IOT hub will reject the connection.
So the best practice is to run ntpclient or ntpd on your embedded device. Even busybox has a simple ntpd implementation, so this should be available on your embedded os. Alternatives are of course to use GPS, a mobile network, a battery-powered RTC or a radio time receiver (FM RDS, long-wave time signals etc.) as a time source. But be aware of the startup and initialization times these time sources take (gps can take several minutes to give a proper time information) and the skew RTCs might accumulate over time. And RTC batteries might die after a couple of years. Also make sure that your time zone is properly set, the SDK will always calculate in UTC times, but if your timezone claims to be UTC but the clock is set to the local time zone, you might be off by a couple of hours.
Which brings me back to the CA cert validity. Today, 2025 seems to be far out in the future, but remember that many embedded devices designed today have a lifetime of over 10 years. So that CA cert will expire in the lifetime of these devices. So make sure you have a way to update the CA certificate.

 Here, you can configure the device via the “control panel” or manage Docker. The initial login information is printed on the side as well. (No big secret here: username “admin”, password “admin”, the device will force you to change the password immediately.) To make things work, you should first check if the clock is set right in the control panel, otherwise you will get a number of strange errors, but their root cause is that the NetPI does not accept any TLS certificates because it thinks they are outside their validity period. So click on control panel, (accept the certificate warnings again) then log in and head to system/time. Now add an NTP server of your preference (I’m using ptbtime1.ptb.de which is the official master clock in Germany) and press “save changes”. Now the clock should update and under “status”, the display should read “Synchronized to time server …” If you don’t do this step, there is a high chance that you won’t be able to run any Docker images since the TLS-based download of the images will fail!
Here, you can configure the device via the “control panel” or manage Docker. The initial login information is printed on the side as well. (No big secret here: username “admin”, password “admin”, the device will force you to change the password immediately.) To make things work, you should first check if the clock is set right in the control panel, otherwise you will get a number of strange errors, but their root cause is that the NetPI does not accept any TLS certificates because it thinks they are outside their validity period. So click on control panel, (accept the certificate warnings again) then log in and head to system/time. Now add an NTP server of your preference (I’m using ptbtime1.ptb.de which is the official master clock in Germany) and press “save changes”. Now the clock should update and under “status”, the display should read “Synchronized to time server …” If you don’t do this step, there is a high chance that you won’t be able to run any Docker images since the TLS-based download of the images will fail!